SayCan by Google
Grounding Language in Robotic Affordances
About SayCan by Google
PaLM-SayCan is the first implementation that uses a large-scale language model to plan for a real robot.
Imagine a robot operating in a kitchen that is capable of executing skills such as "pick up the coffee cup" or "go to the sink". To get the robot to use these skills to perform a complex task (e.g. "I spilled my drink, can you help?"), the user could manually break it up into steps consisting of these atomic commands. However,this would be exceedingly tedious. A language model can split the high-level instruction ("I spilled my drink, can you help?") into sub-tasks, but it cannot do that effectively unless it has the context of what the robot is capable of given the abilities, current state of the robot and its environment.
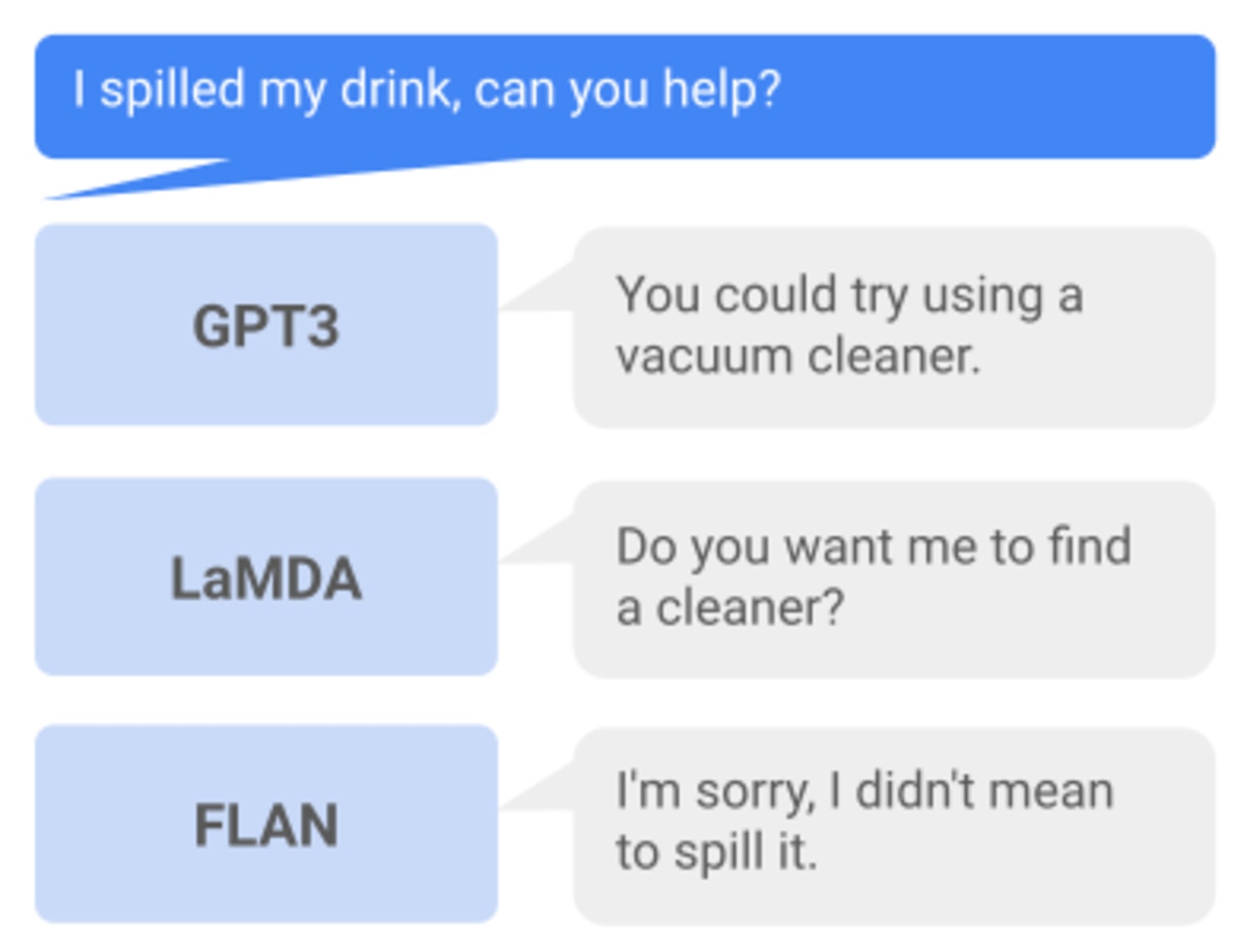
When querying existing large language models like GPT-3, we see that a language model queried with "I spilled my drink, can you help?" may respond with "You could try using a vaccuum cleaner" or "I'm sorry, I didn't mean to spill it".
While these responses sound reasonable, they are not feasible to execute with the robot's capabilities in its current environment.
The main principle that we use to connect LLMs to physical tasks is to observe that, in addition of asking the LLM to simply interpret an instruction, we can use it to score the likelihood that an individual skill makes progress towards completing the high-level instruction. Furthermore, if each skill has an accompanying affordance function that quantifies how likely it is to succeed from the current state (such as a learned value function), its value can be used to weight the skill's likelihood.
Once the skill is selected, we execute it on the robot, the process proceeds by iteratively selecting a task and appending it to the instruction. Practically, we structure the planning as a dialog between a user and a robot, in which a user provides the high level-instruction, e.g. "How would you bring me a coke can?" and the language model responds with an explicit sequence e.g. "I would: 1. Find a coke can, 2. Pick up the coke can, 3. Bring it to you, 4. Done". In summary, given a high-level instruction, SayCan combines probabilities from a language model (representing the probability that a skill is useful for the instruction) with the probabilities from a value function (representing the probability of successfully executing said skill) to select the skill to perform. This emits a skill that is both possible and useful. The process is repeated by appending the selected skill to robot response and querying the models again, until the output step is to terminate.
Source: https://say-can.github.io/

